Achieving High Contextual Accuracy on Code Generation

Lune Team
@lune_inc

TLDR;
Individual Lunes are now available as MCP servers. Lunes consistently outperform standalone SOTA LLMs on context-aware code generation, use them inside Cursor, Windsurf, and more.
The Current Challenge With LLMs
LLMs often hallucinate information not in their training data, leading to inaccurate answers about up-to-date libraries or documentation. This is especially prevalent when working with new libraries/frameworks, or those that are less documented.
What We Are Building
At Lune, we're addressing this challenge by creating specialized retrieval agents called "Lunes" built on knowledge sources including:
- Codebases
- Documentation
- Popular developer packages
- Libraries, frameworks, and APIs
- Forum discussions
Our latest release, allow you to use each Lune as an MCP server within Cursor, Windsurf, Claude Desktop, or any other tool that supports MCP.
Evaluating Lune MCPs vs Popular Models
We compared the accuracy of standalone models against domain-specific Lunes for four popular libraries / APIs:
Standalone Models:
- Anthropic Claude 3.7 Sonnet
- OpenAI O3-mini
- Perplexity Sonar (Fine-tuned LLM grounded in search)
Domain-Specific Lunes:
- Langfuse
- Mastra
- Stripe
- Ragflow
Methodology
- Data Collection: Scraped and parsed relevant markdown documentation for each library into structured datasets.
- Question Generation: Used a structured prompt-driven approach to create a dataset of question, answer, and correct answer critieras.
- Testing: Randomly selected 200 questions from each dataset to test each model.
- Evaluation: Used Gemini-2.0 Flash as an independent scoring model with standardized evaluation criteria.
Evaluation Protocol
The following prompt was used to generate our test data:
function ExtractInterviewQuestions(markdown: string, lune_name: string, lune_description: string) -> InterviewQuestions {
client "openai/o3-mini"
prompt #"
You are tasked with generating high-quality technical interview questions based on a specific page of documentation/code about {{ lune_name }} - {{ lune_description }}. The documentation is provided in markdown format below.
Your goal is to create standalone questions that test a deep understanding of the technical concepts, code usage, features, and usage of {{ lune_name }}, as presented in this documentation/code page. The questions should be:
- Directly related to {{ lune_name }} and its functionalities, code implementations, integrations, or capabilities and grounded in concepts from this specific page of documentation/code.
- Standalone, meaning they do not reference 'the documentation' or 'the page.' They should make sense in a general technical interview about {{ lune_name }}.
- Specific and precise, with clear, unambiguous answers that can be derived from documentation/code that you are given.
- Focused on understanding rather than memorization (e.g., how something works or why it’s useful, not just recalling facts).
- When appropriate (the page shows code implementations, code usage, and code examples), ask questions about code implementations, code usage, and code examples of {{ lune_name }} based only on the provided page of documentation/code.
- About technical aspects of {{ lune_name }}, such as its usage, features, integrations, code implementation, or performance.
- For code snippets, use markdown code blocks. If your generated question references a code snippet, INCLUDE THE CODE SNIPPET IN THE QUESTION.
IMPORTANT: Questions MUST be as specific as possible and MUST be grounded in the documentation/code that you are given. If the question is about a code snippet, make sure to include the actual code in the question so the question can be answered without referencing the page of documentation/code.
Avoid questions that:
- Focus on the structure or navigation of the documentation pages itself (e.g., 'What sections are on the page?').
- Are off-topic or primarily about other tools/libraries mentioned in passing (e.g., not about {{ lune_name }}).
- Test memorization of trivial details (e.g., 'Name one thing listed...') rather than understanding the concepts.
- Are vague or open-ended with multiple possible interpretations.
- Do not include full context required to answer the question (e.g., 'What does the code above do?' without the code above).
IMPORTANT: If the documentation page lacks sufficient technical content to generate high-quality questions that meet the above criteria, output a single QA pair with empty strings for 'question', 'answer', and 'criteria', like this:
{
"qa_pairs": [
{
"question": "",
"answer": "",
"criteria": ""
}
]
}
Here is the markdown of the documentation/code reference page:
{{ markdown }}
Generate the questions, answers, and evaluation criteria in JSON format, with a key 'qa_pairs' containing an array of objects, each with 'question', 'answer', and 'criteria' fields:
- The 'question' should be a standalone, specific, and precise technical question based on the documentation.
- The 'answer' should provide the correct response to the question, grounded in the documentation.
- The 'criteria' should be a concise list of the key elements that a correct answer must include, such as specific syntax, important concepts, or critical details from the documentation. This list will help graders determine if a candidate’s response demonstrates a sufficient understanding of the topic.
Ensure that the questions test a deep understanding of {{ lune_name }} and are directly related to its functionalities, code implementations, integrations, or capabilities as described in the provided documentation.
Examples of good questions:
- 'Is BLANK integration for {{ lune_name }} supported?'
- 'How much does FEATURE cost for {{ lune_name }}'
Examples of bad questions to avoid:
- 'Which integrations are mentioned in the documentation?'
- 'What is SOME_OTHER_TOOL as mentioned on the page?'
{{ ctx.output_format }}
"#
}The following prompt was used to evaluate model outputs using Gemini 2.0 Flash:
async def evaluate_answer(self, question: str, correct_answer: str, generated_answer: str) -> bool:
prompt = f"""
You are an instructor that evaluates the correctness of an answer from a technical interview.
The question is: {question}
The correct answer is: {correct_answer}
The candidate's answer is: {generated_answer}
Please evaluate the candidate's answer strictly against the correct answer and output in json, a simple bool value (is_answer_correct) indicating if the answer is correct or not and a string (reasoning) explaining your reasoning concisely.
"""
response = await self.client.beta.chat.completions.parse(
model="gemini-2.0-flash",
messages=[
{
"role": "user",
"content": prompt
}
],
response_format=AnswerValidation,
)
evaluation = response.choices[0].message.parsed
return evaluation.is_answer_correct
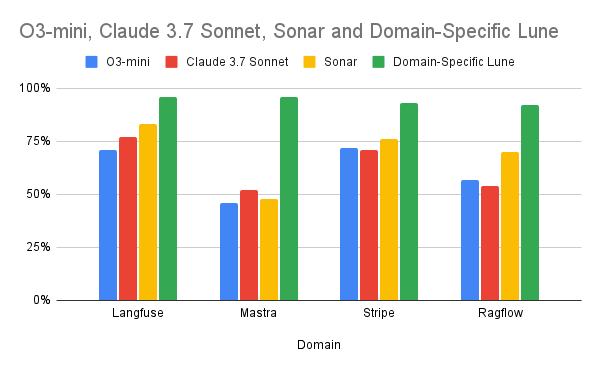
Evaluation Results
The performance results indicated significant advantages for the domain-specific Lunes across all evaluated datasets:
| Topic | O3-mini | Claude 3.7 Sonnet | Sonar | Lunes |
|---|---|---|---|---|
| Langfuse | 71% | 77% | 83% | 96% |
| Mastra | 46% | 52% | 48% | 96% |
| Stripe | 72% | 71% | 76% | 93% |
| Ragflow | 57% | 54% | 70% | 92% |
Access the full data sets for all four topics here:
Conclusion
From this testing, we see that using Lunes gives you a considerable boost in contextual accuracy. We can also see that Perplexity Sonar performs on average, slightly better than the other three standard LLMs.
You can see our open-source MCP integration here
Or use the following command
npx -y @lune-inc/mcp --api-key=YOUR_LUNE_API_KEY --lune-name=LUNE_NAME --lune-id=LUNE_IDYou can also chat with Lunes here.